Un asistente de IA que responde sobre todo el catálogo de un distribuidor industrial — sin inventarse nada
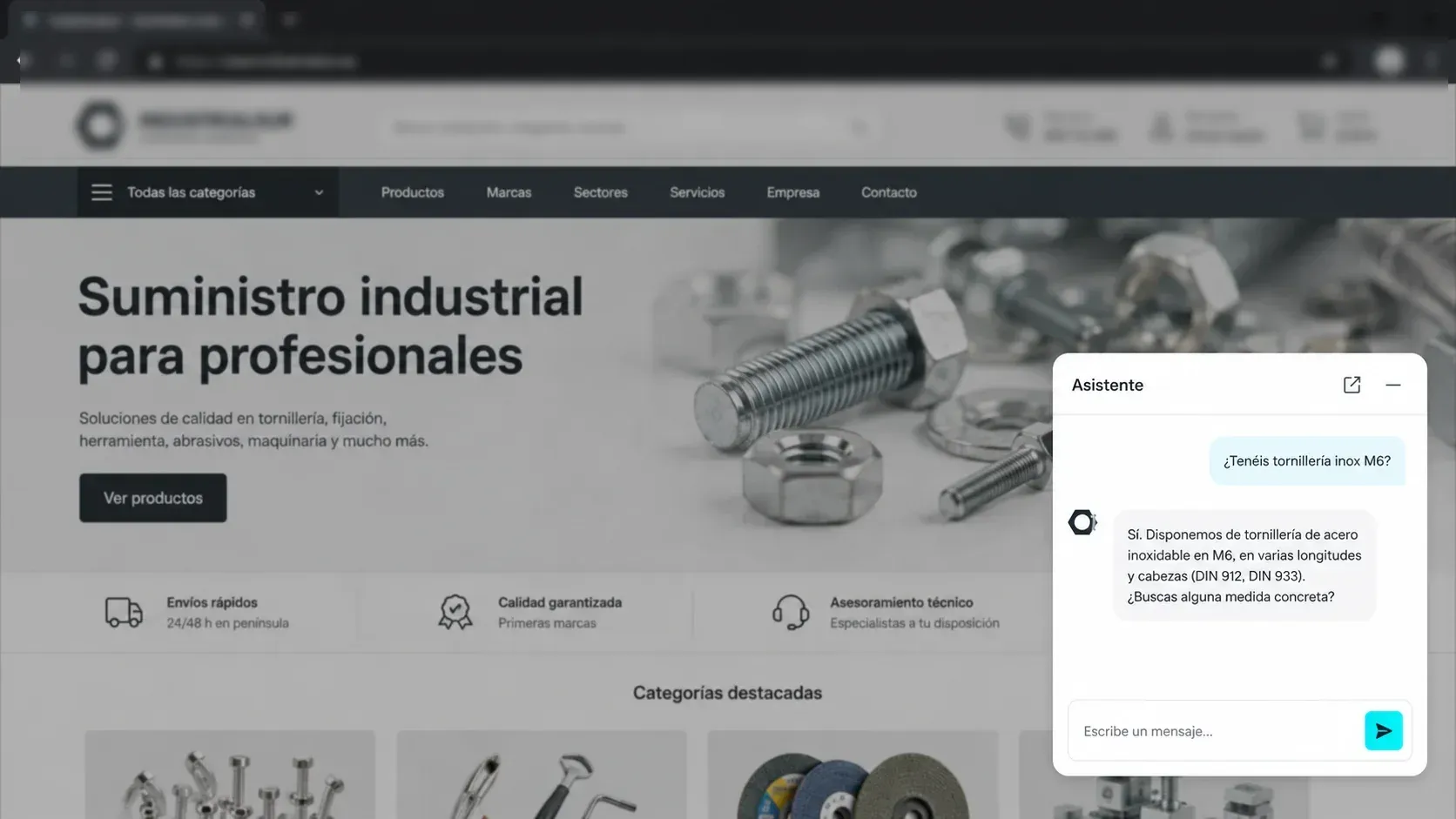
Un distribuidor de suministro industrial de Gipuzkoa —tornillería, herramienta, abrasivos, fijaciones, material de seguridad— con un catálogo de varios miles de referencias que vende a talleres, mantenimiento industrial e instaladores.
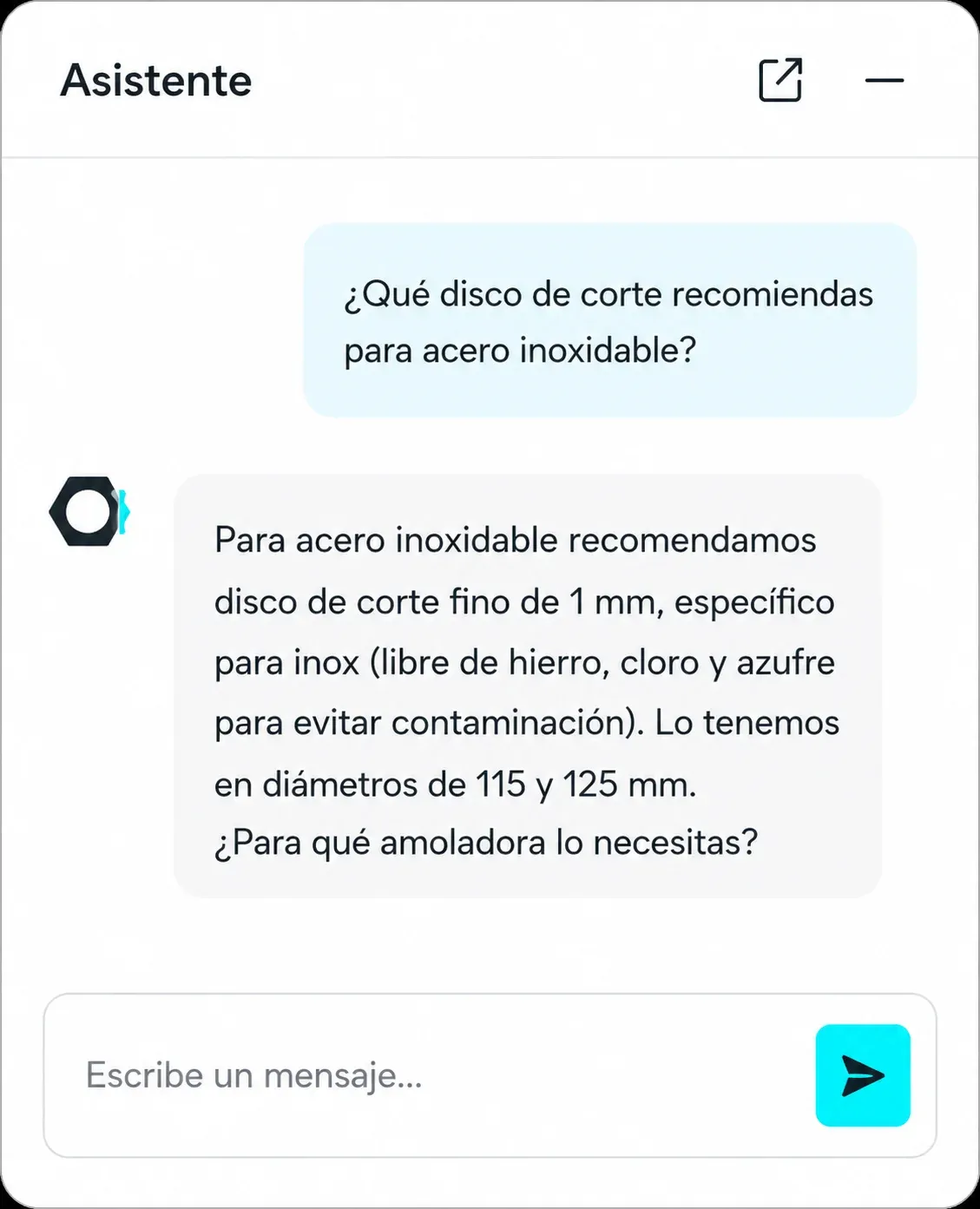
El problema no era la falta de información, era lo contrario: hay demasiada y está repartida. Catálogos en PDF de cada fabricante, una base de datos con miles de productos y sus especificaciones, fichas técnicas, y toda la web. Un comercial veterano se sabe medio catálogo de memoria. Pero un comercial nuevo, o un cliente entrando en la web un martes a las once de la noche, no tiene a quién preguntarle "¿qué broca uso para inox de 8 milímetros?" o "¿tenéis tornillería DIN 912 en M6?".
La pregunta tiene respuesta. Está en algún sitio. Pero encontrarla rápido, y fiarte de que es la correcta, es justo lo que faltaba.
El problema de fondo (y por qué un chatbot normal no vale)
Aquí está el reto que tiene todo asistente corporativo serio, y conviene explicarlo sin humo: un modelo de lenguaje, por potente que sea, no sabe lo que hay en el catálogo de este distribuidor. No lo ha visto nunca. Si le preguntas sin más, te dará una respuesta que suena bien y se inventa la mitad — productos que no existen, referencias que no vende, datos que no son.
Para una empresa, eso no es una curiosidad técnica: es el riesgo que hace que un chatbot pase de activo a problema. Si el asistente le dice a un cliente que tienes un producto que no tienes, o le da una especificación equivocada, has empeorado la experiencia, no la has mejorado.
La solución correcta para este caso no es entrenar un modelo (caro, lento, y desactualizado en cuanto cambia un precio). Es darle al modelo la información real en el momento exacto de cada pregunta, y obligarle a responder solo con eso. Eso es RAG.
Qué hice
Construí un sistema RAG —Retrieval-Augmented Generation— a medida. En cristiano: un asistente que, antes de responder, busca la información real del cliente y redacta la respuesta apoyándose únicamente en lo que ha encontrado. Pero el "qué" técnico es lo de menos; lo que marca la diferencia son las decisiones.
Unifiqué cuatro fuentes dispersas en una sola memoria
El conocimiento del asistente se alimenta de cuatro orígenes que antes vivían cada uno por su lado: los catálogos en PDF de los fabricantes, la base de datos de productos (extraída directamente de la fuente, con sus especificaciones reales, no de un scraping aproximado), la información de empresa (horarios, contacto, condiciones) y la web. Todo convertido a un formato que el sistema puede buscar por significado, no solo por palabra exacta. Por primera vez, todo el conocimiento de la empresa es consultable de un tirón.
Le enseñé a buscar mejor de lo que pregunta el usuario
Las preguntas reales son cortas y pobres: "¿tenéis tacos químicos?". Una búsqueda literal con eso encuentra poco. Así que metí una técnica (se llama HyDE) por la que el sistema, antes de buscar, redacta internamente una respuesta hipotética con el vocabulario correcto del sector, y busca con esa. El resultado: encuentra lo relevante aunque el cliente pregunte en dos palabras. Es la diferencia entre un buscador que se queda corto y uno que entiende lo que querías decir.
Resolví el caso que rompe a la mayoría: "lístame todo"
Cuando alguien pide "enséñame todas las categorías que tenéis", una búsqueda normal por relevancia falla — devuelve unas pocas y se deja el resto. Detecté ese tipo de pregunta y le di un camino propio: en vez de buscar por relevancia, recorre el catálogo entero y devuelve la lista completa, con una instrucción explícita de no resumir ni omitir. Una cosa es responder una duda concreta y otra dar el inventario completo; el sistema sabe cuándo hace cada una.
Lo blindé contra inventar
Esta es la pieza clave para una empresa. El sistema tiene instrucciones estrictas de responder solo con la información que ha recuperado, y de decir con claridad "no tengo ese dato" cuando no lo tiene, en vez de rellenar el hueco con algo verosímil. Nada de productos inventados, nada de precios imaginados. Si no está en los datos del cliente, el asistente no se lo saca de la manga.
Lo conecté para que se mantenga solo
Un asistente que responde con datos reales tiene un enemigo silencioso: quedarse desactualizado. Si cada vez que entra un producto nuevo hay que re-alimentar el sistema a mano, acaba abandonado y respondiendo con catálogo viejo. Así que lo automaticé: cuando se sube o se modifica contenido —un producto, una página, una ficha—, ese cambio entra en la memoria del asistente sin que nadie tenga que hacer nada. El catálogo del chatbot y el catálogo real se mantienen sincronizados solos. El sistema no es una foto de un día; está vivo y al día sin trabajo manual.
Lo dejé embebible y barato
El asistente es un widget que se cuelga en cualquier web con una sola línea, con un diseño limpio que no desentona. Y el coste de operación es ridículo para lo que hace: la infraestructura corre en un servidor propio, los buscadores y la base de datos son autoalojados y sin licencia, y el único gasto variable real es el uso del modelo de IA. Hablamos de unas pocas decenas de euros al mes para varios miles de consultas — frente al coste de entrenar o mantener modelos propios, que está en otra liga.
El detalle que más cuesta y nadie ve
El reto interesante fue el idioma. Los nombres de producto y de gama —muchos en clave técnica o medio en otro idioma— confundían al detector automático de idioma del sistema, que de vez en cuando contestaba en inglés o italiano a un cliente que había preguntado en castellano. En vez de pelearme con reglas frágiles, tomé la decisión de raíz: forzar que el asistente responda siempre en español. Resolvió el bug de un plumazo y, de paso, encajaba con lo que el cliente quería. La solución correcta no siempre es la más sofisticada; a veces es la que entiende el caso concreto.
Resultado en cifras
Conocimiento consultable — Miles de fragmentos del catálogo real, buscables en milisegundos
Fuentes unificadas — Cuatro: PDF de fabricantes, base de datos, info de empresa y web
Mantenimiento — Ingesta automática: el contenido nuevo entra solo, sin re-alimentar a mano
Fiabilidad — Respuestas ancladas a datos reales, sin inventar productos ni precios
Integración — Widget embebible con una línea, sin cookies y sin banner
Coste operativo — Pocas decenas de € al mes para varios miles de consultas
Estado — Sistema funcionando, desplegado en servidor propio con HTTPS